xan: Efficient CSV Processing at Your Command Line
Primary Purpose:
xan is a high-performance command-line tool designed for efficient processing of CSV files. Built with Rust, it excels in speed and memory efficiency, making it ideal for handling large datasets seamlessly.
Key Features:
Rust-Powered Efficiency: Leverages Rust's performance capabilities, a novel SIMD parser, and multithreading to ensure rapid processing even with gigabytes of data.
Versatile Command Set: Offers a wide range of commands for previewing, filtering, aggregating, sorting, and joining CSV files, allowing complex operations through composable chains.
Advanced Expression Language: Enables complex tasks with a tailored language optimized for CSV data, surpassing the speed of dynamically-typed languages like Python or JavaScript.
Format Flexibility: Supports various CSV-adjacent formats (e.g., .cdx, bioinformatics files) and converts to/from formats such as JSON, Excel, and numpy arrays.
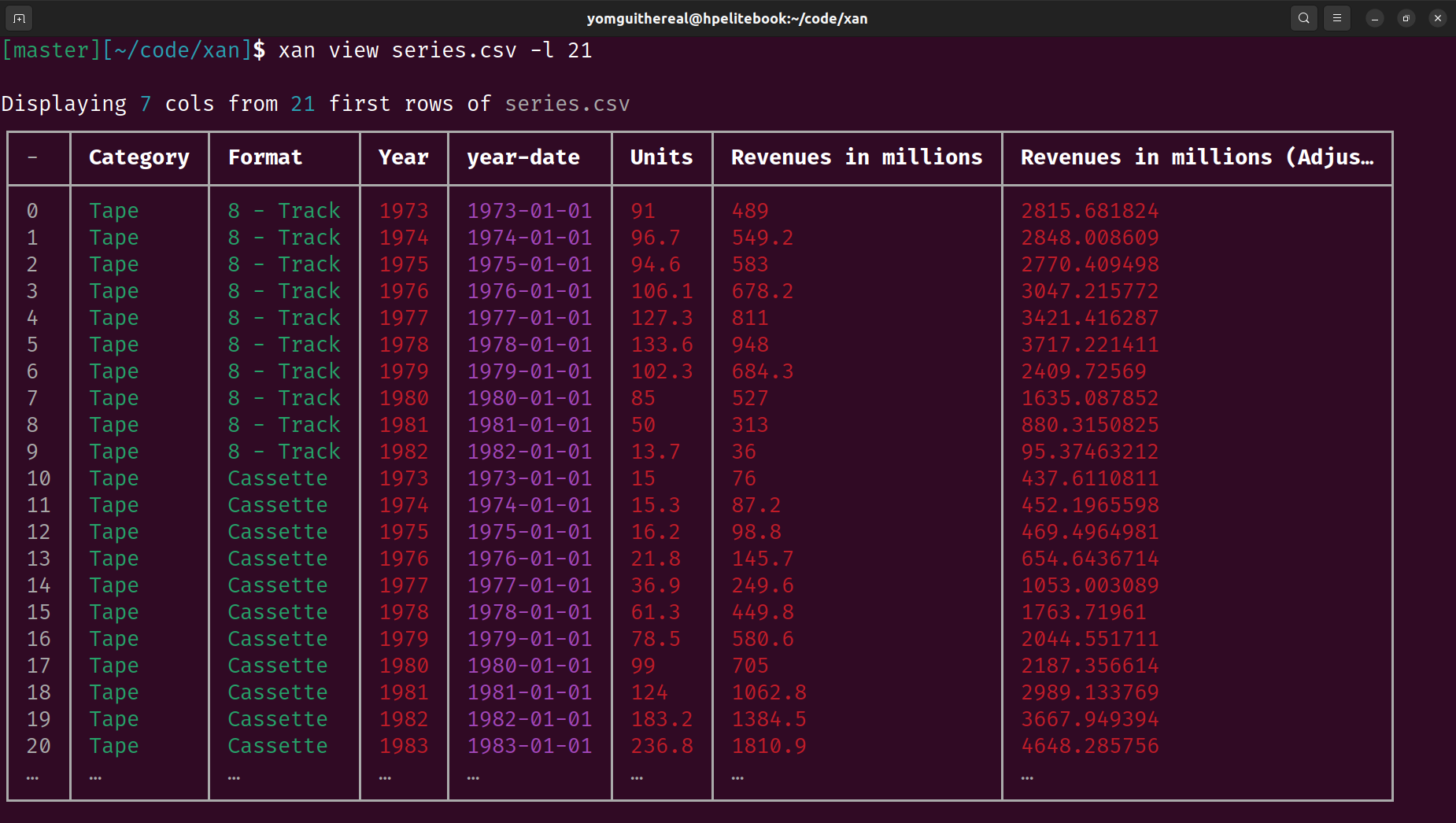
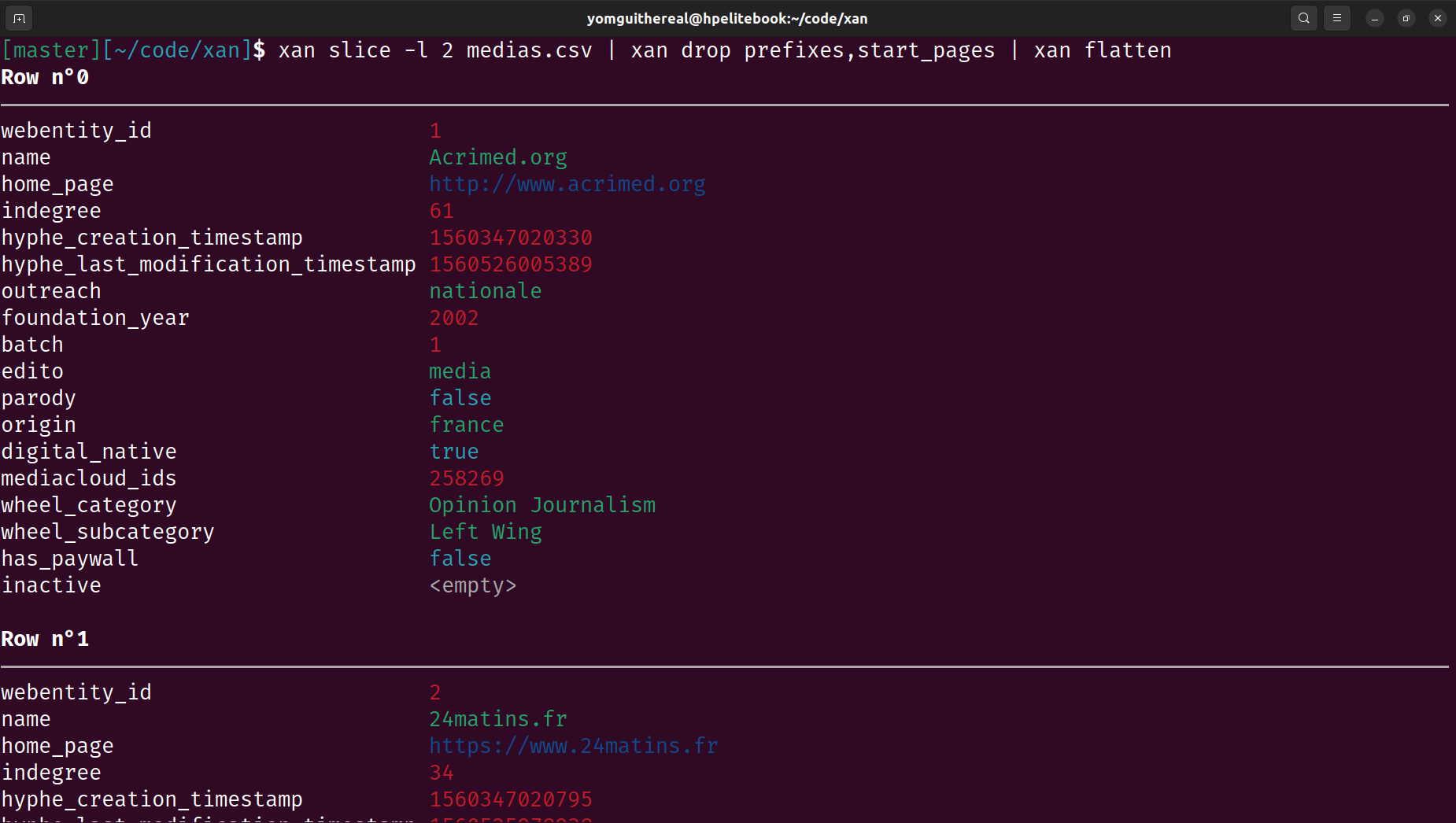
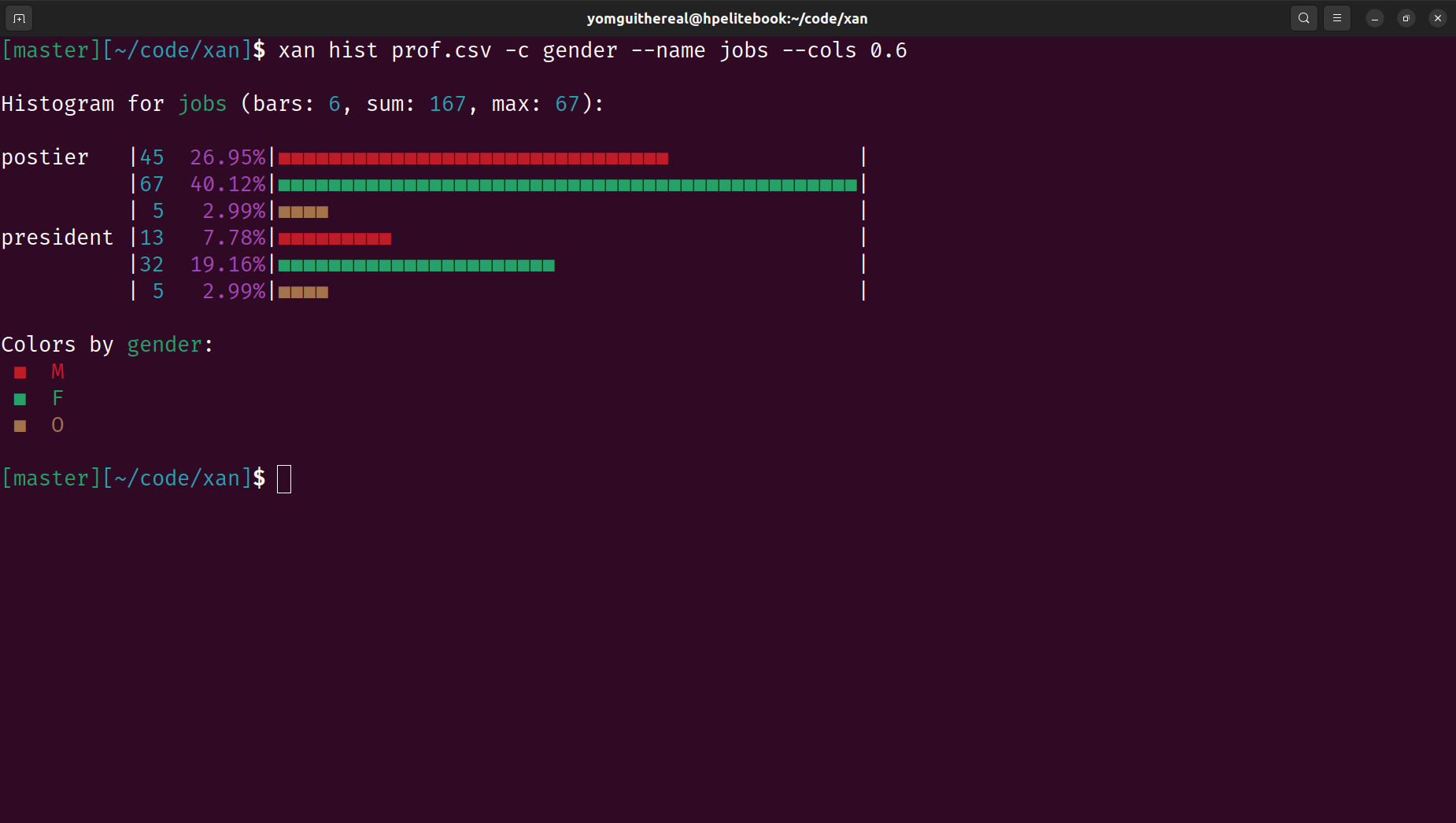
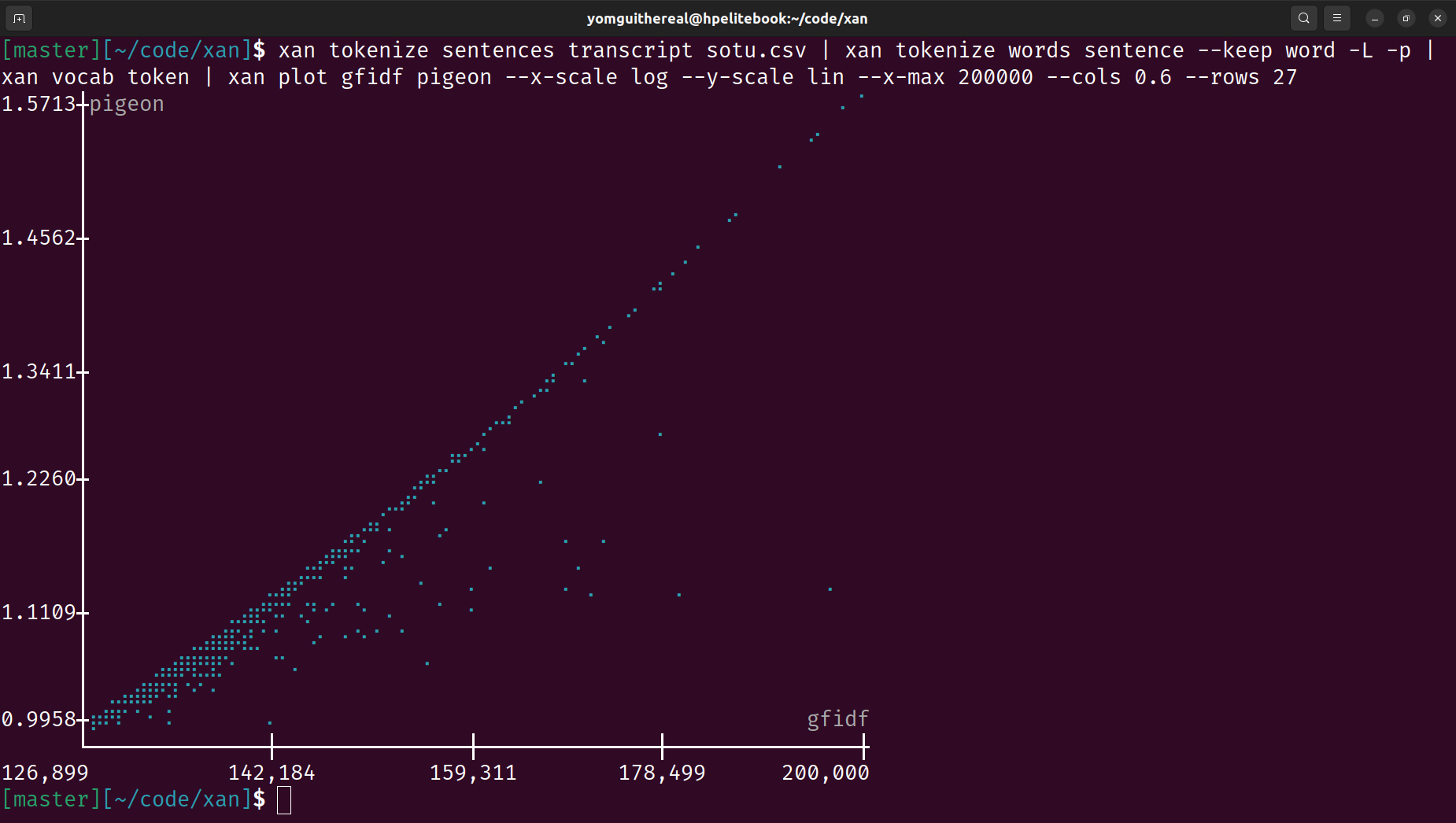
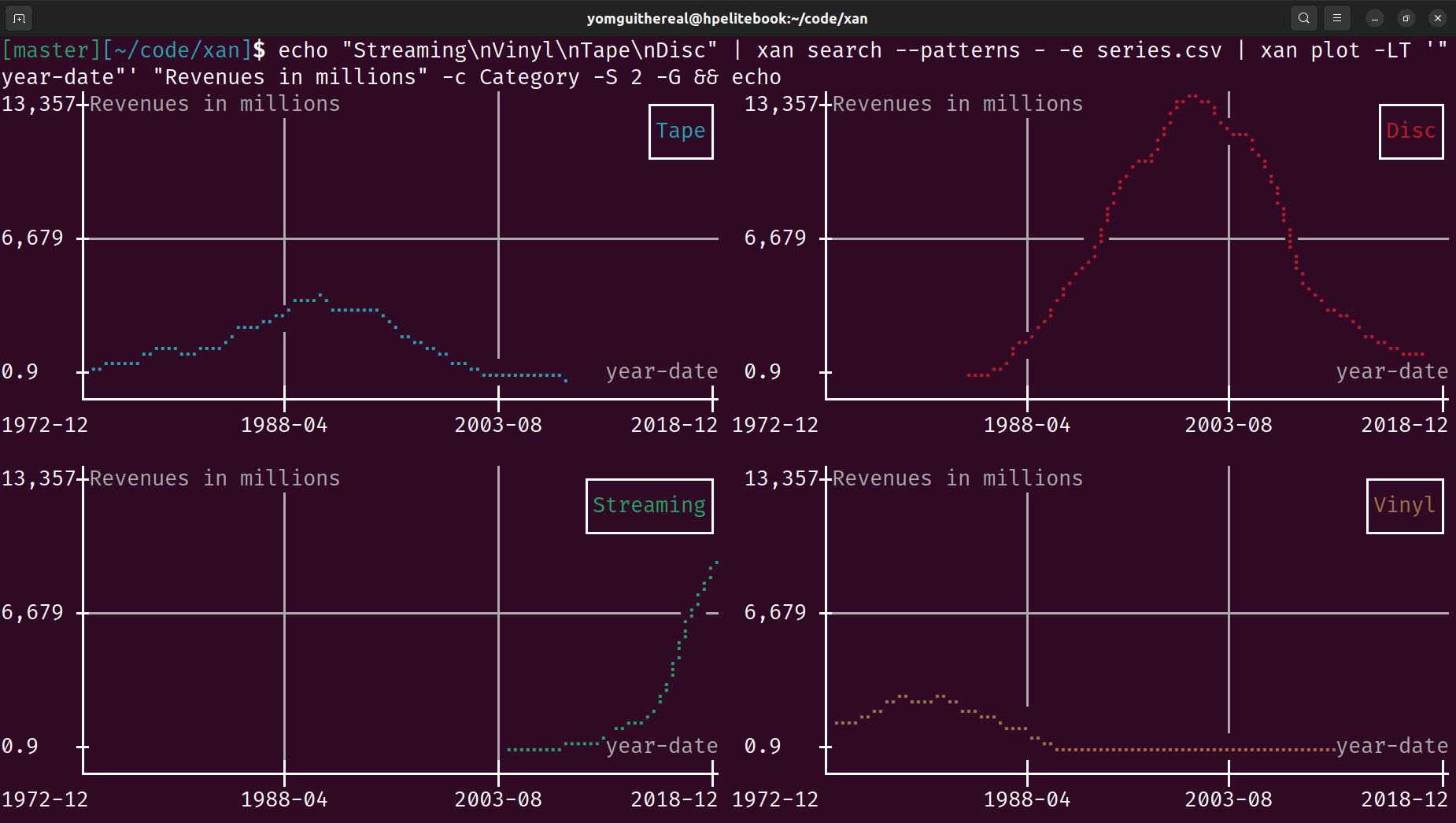
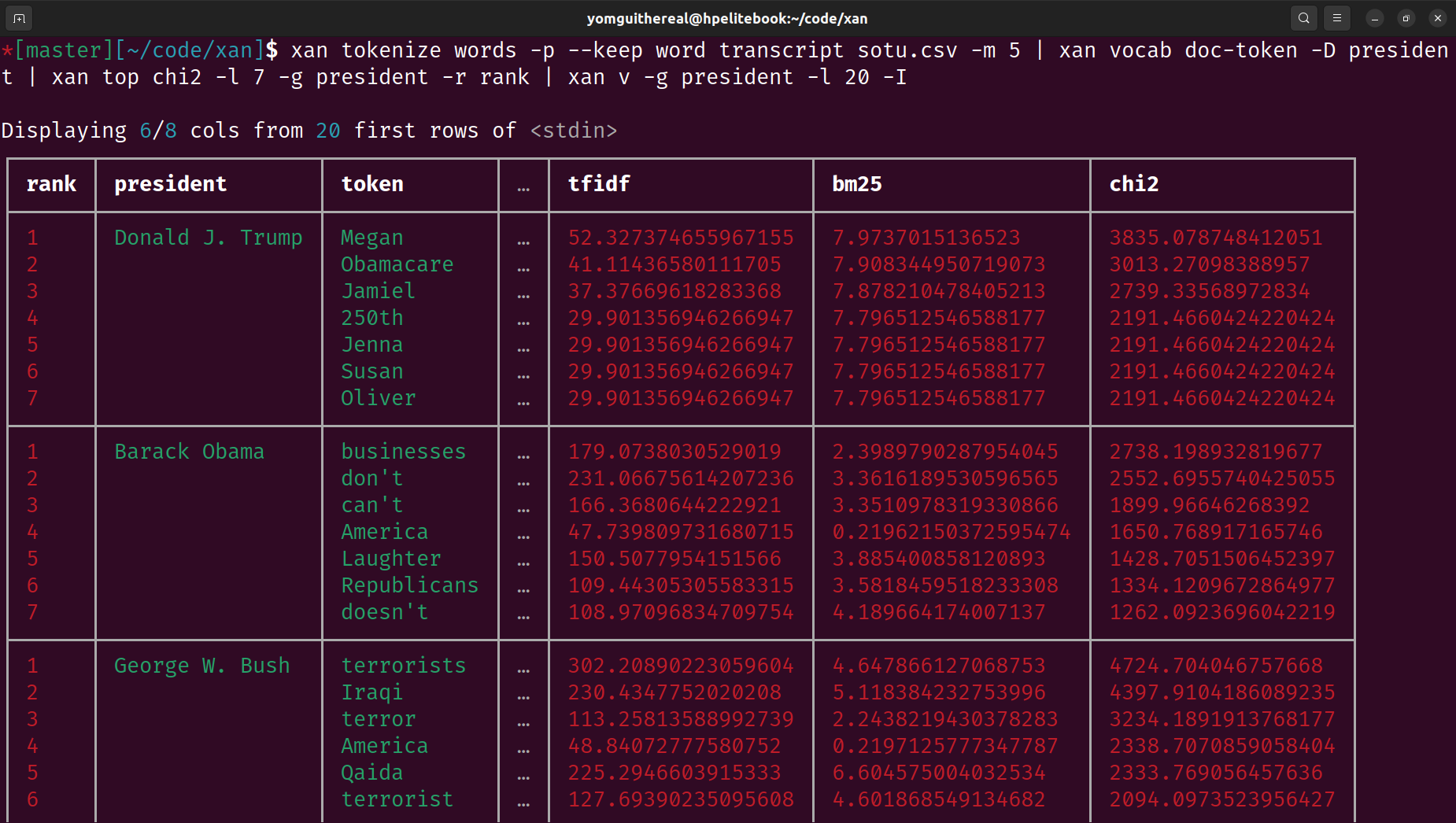
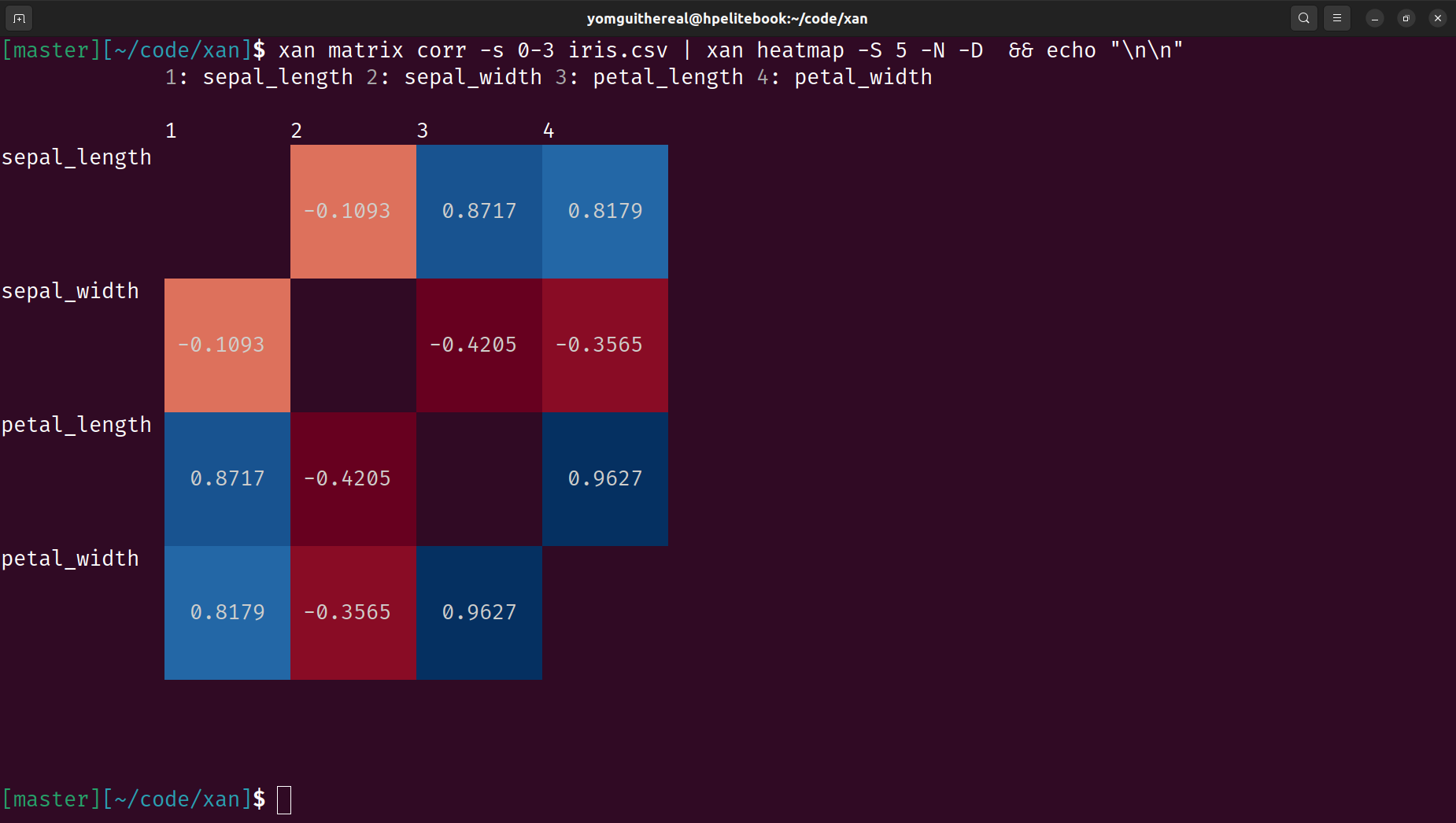
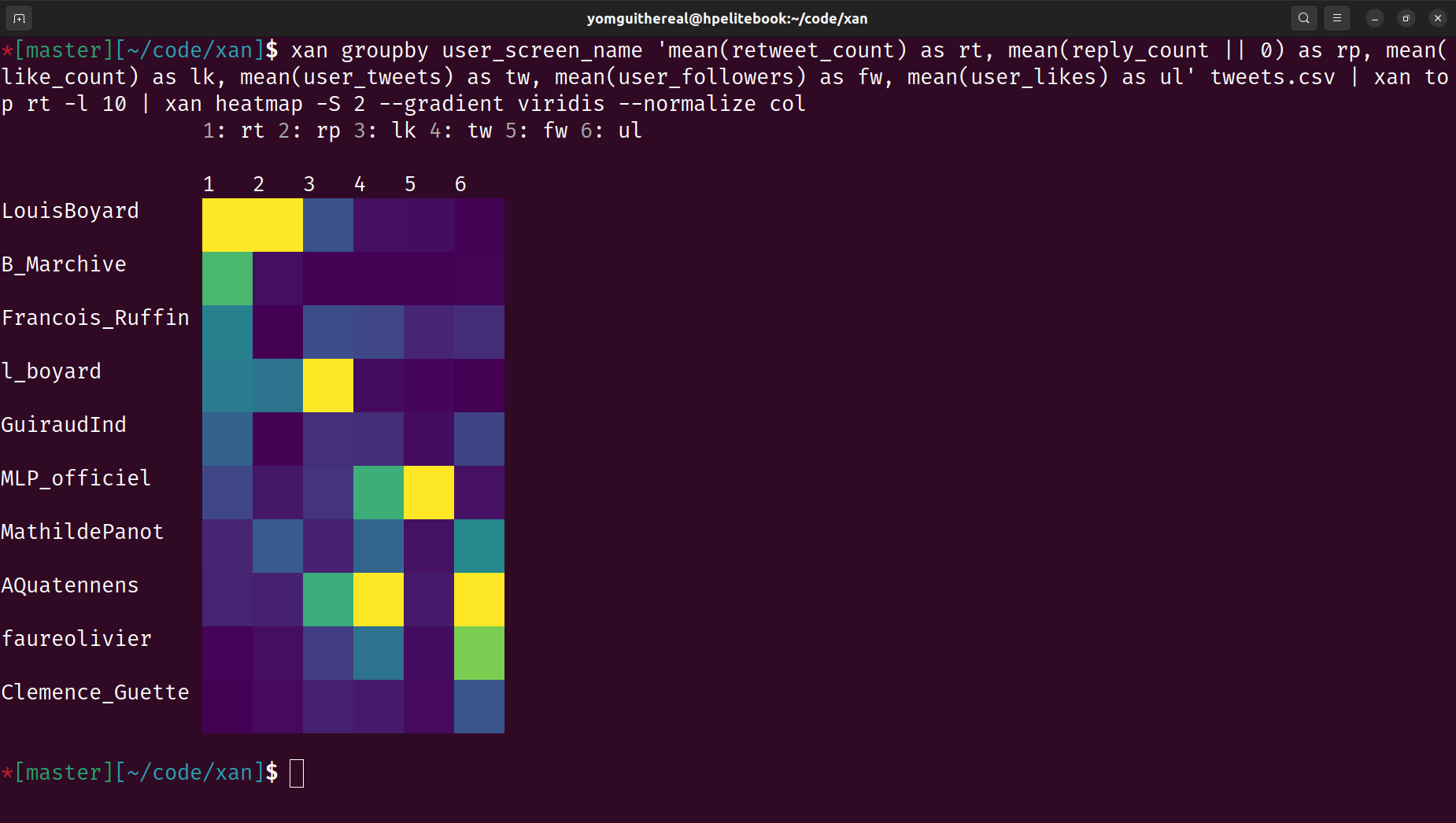
Terminal Visualization: Displays CSV files directly in the terminal for easy exploration and creates basic visualizations like histograms and heatmaps.
Audience & Benefit:
Tailored for data analysts, researchers, and developers managing large or complex CSV datasets, xan provides a robust toolkit that enhances productivity. Its speed, efficiency, and versatile features enable users to process data swiftly and effectively, saving time while handling intricate tasks with ease.
README
xan, the CSV magician
xan is a command line tool that can be used to process CSV files directly from the shell.
It has been written in Rust to be as fast as possible, use as little memory as possible, and can very easily handle large CSV files (Gigabytes). It leverages a novel SIMD CSV parser and is also able to parallelize some computations (through multithreading) to make some tasks complete as fast as your computer can allow.
It can easily preview, filter, slice, aggregate, sort, join CSV files, and exposes a large collection of composable commands that can be chained together to perform a wide variety of typical tasks.
xan also offers its own expression language so you can perform complex tasks that cannot be done by relying on the simplest commands. This minimalistic language has been tailored for CSV data and is way faster than evaluating typical dynamically-typed languages such as Python, Lua, JavaScript etc.
Note that this tool is originally a fork of BurntSushi's xsv, but has been nearly entirely rewritten at that point, to fit SciencesPo's médialab use-cases, rooted in web data collection and analysis geared towards social sciences (you might think CSV is outdated by now, but read our love letter to the format before judging too quickly).
xan therefore goes beyond typical data manipulation and expose utilities related to lexicometry, graph theory and even scraping.
Beyond CSV data, xan is able to process a large variety of CSV-adjacent data formats from many different disciplines such as web archival (.cdx) or bioinformatics (.vcf, .gtf, .sam, .bed etc.). xan is also able to convert to & from many data formats such as json, excel files, numpy arrays etc. using xan to and xan from. See section for more detail.
A package is available from the official repositories. To install xan simply run:
pkgin install xan
Nix
xan is packaged for Nix, and is available in Nixpkgs as of 25.05 release. To
install it, you may add it to your environment.systemPackages as pkgs.xan or
use nix-shell to enter an ephemeral shell.
nix-shell -p xan
Pixi (Linux, macOS, Windows)
xan can be installed in Linux, macOS, and Windows using the Pixi package manager:
pixi global install xan
Pre-built binaries
Pre-built binaries can be found attached to every GitHub releases.
Currently supported targets include:
x86_64-apple-darwin
x86_64-unknown-linux-gnu
x86_64-unknown-linux-musl
x86_64-pc-windows-msvc
aarch64-apple-darwin
aarch64-unknown-linux-gnu
ppc64le targets are not built by the CI yet but prebuilt binaries can still be found in the conda-forge package's files if you need them.
Feel free to open a PR to improve the CI by adding relevant targets.
Installing completions
Note that xan also exposes handy automatic completions for command and header/column names that you can install through the xan completions command.
Run the following command to understand how to install those completions:
xan completions -h
# With zsh you might also need to add this to your initialization to make
# sure Bash compatibility is loaded:
autoload -Uz bashcompinit && bashcompinit
Quick tour
Let's learn about the most commonly used xan commands by exploring a corpus of French medias:
To access the expression language's cheatsheet, run xan help cheatsheet. To display the full list of available functions, run xan help functions.
Performing custom aggregation
xan agg 'sum(indegree) as total_indegree, mean(indegree) as mean_indegree' medias.csv | xan view -I
Displaying 1 col from 1 rows of
┌────────────────┬───────────────────┐
│ total_indegree │ mean_indegree │
├────────────────┼───────────────────┤
│ 25987 │ 56.12742980561554 │
└────────────────┴───────────────────┘
To access the expression language's cheatsheet, run xan help cheatsheet. To display the full list of available functions, run xan help functions. Finally, to display the list of available aggregation functions, run xan help aggs.
Grouping rows and performing per-group aggregation
xan groupby edito 'sum(indegree) as indegree' medias.csv | xan view -I
Displaying 1 col from 5 rows of
┌────────────┬──────────┐
│ edito │ indegree │
├────────────┼──────────┤
│ agence │ 50 │
│ agrégateur │ 459 │
│ plateforme │ 658 │
│ media │ 24161 │
│ individu │ 659 │
└────────────┴──────────┘
To access the expression language's cheatsheet, run xan help cheatsheet. To display the full list of available functions, run xan help functions. Finally, to display the list of available aggregation functions, run xan help aggs.
If you ever feel lost, each command has a -h/--help flag that will print the related documentation.
If you need help about the expression language, check out the help command itself:
# Help about help ;)
xan help --help
Regarding input & output formats
All xan commands expect a "standard" CSV file, e.g. comma-delimited, with proper double-quote escaping. This said, xan is also perfectly able to infer the delimiter from typical file extensions such as .tsv, .tab, .psv, .ssv or .scsv.
If you need to process a file with a custom delimiter, you can either use the xan input command or use the -d/--delimiter flag available with all commands.
If you need to output a custom CSV dialect (e.g. using ; delimiters), feel free to use the xan fmt command.
If your CSV file has a varying number of columns per row, use the xan fixlengths command before piping into other commands as xan expects well-behaved CSV data where rows all have the same number of columns.
Finally, even if most xan commands won't even need to decode the file's bytes, some might still need to. In this case, xan will expect correctly formatted UTF-8 text. Please use iconv or other utils if you need to process other encodings such as latin1 ahead of xan.
Working with headless CSV file
Even if this is good practice to name your columns, some CSV file simply don't have headers. Most commands are able to deal with those file if you give the -n/--no-headers flag.
Note that this flag always relates to the input, not the output. If for some reason you want to drop a CSV output's header row, use the xan behead command.
Regarding stdin
By default, all commands will try to read from stdin when the file path is not specified. This makes piping easy and comfortable as it respects typical unix standards. Some commands may have multiple inputs (xan join, for instance), in which case stdin is usually specifiable using the - character:
# First file given to join will be read from stdin
cat file1.csv | xan join col1 - col2 file2.csv
Note that the command will also warn you when stdin cannot be read, in case you forgot to indicate the file's path.
Regarding stdout
By default, all commands will print their output to stdout (note that this output is usually buffered for performance reasons).
In addition, all commands expose a -o/--output flag that can be use to specify where to write the output. This can be useful if you do not want to or cannot use > (typically in some Windows shells). In which case, - as a output path will mean forwarding to stdout also. This can be useful when scripting sometimes.
Supported file formats
xan is able to process a large variety of CSV-adjacent data formats out-of-the box:
.csv files will be understood as comma-separated
.tsv & .tab files will be understood as tab-separated
.scsv & .ssv files will be understood as semicolon-separated
.psv files will be understood as pipe-separated
.cdx files (an index file format related to web archive) will be understood as space-separated and will have its magic bytes dropped
.ndjson & .jsonl files will be understood as tab-separated, headless, null-byte-quoted, so you can easily use them with xan commands (e.g. parsing or wrangling JSON data using the expression language to aggregate, even in parallel). If you need a more thorough conversion of newline-delimited JSON data, check out the xan from -f ndjson command instead.
.vcf files (Variant Call Format) from bioinformatics are supported out of the box. They will be stripped of their header data and considered as tab-delimited.
.gtf & .gff2 files (Gene Transfert Format) from bioinformatics are supported out of the box. They will be stripped of their header data and considered as headless & tab-delimited.
.sam files (Sequence Alignment Map) from bioinformatics are supported out of the box. They will be stripped of their header data and considered as headless & tab-delimited.
.bed files (Browser Extensible Data) from bioinformatics are supported out of the box. They will be stripped of their header data and considered as headless & tab-delimited.
Note that more exotic delimiters can always be handled using the ubiquitous -d, --delimiter flag.
Some additional formats (e.g. .gff, .gff3) are also supported but must first be normalized using the xan input command because their cells must be trimmed or because they have comment lines to be skipped.
Note also that UTF-8 BOMs ara always stripped from the data when processed.
Compressed files
xan is able to read gzipped files (having a .gz extension). It is also able to leverage .gzi indices (usually created through bgzip) when seeking is necessary (constant time reversing, parallelization etc.).
xan is also able to read files compressed with Zstdandard (having a .zst extension).
Regarding color
Some xan commands print ANSI colors in the terminal by default, typically view, flatten, etc.
All those commands have a standard --color=(auto|always|never) flag to tweak the colouring behavior if you need it (note that colors are not printed when commands are piped, by default).
They also respect typical environment variables related to ANSI colouring, such as NO_COLOR, CLICOLOR & CLICOLOR_FORCE, as documented here.